
虽然反向传播是现代人工智能和机器学习中不可或缺的工具,但它的历史跨越数十年,涉及众多科学突破。其概念性发展始于 20 世纪 60 年代,但在 20 世纪 80 年代中期,在 Frank Rosenblatt、Seppo Linnainmaa 和 Paul Werbos 等研究人员做出奠基性贡献和普及之后,才获得广泛关注。
早期理论基础
反向传播的理论基础早在 20 世纪 60 年代就已出现,这要归功于不同领域研究人员的工作。Frank Rosenblatt 做出了早期且概念相关的贡献,他因开发 Perceptron(感知器) 而闻名,感知器是神经网络的简单模型。1962 年,他描述了一种用于其多层感知器思想的“反向传播误差校正”程序。虽然单层感知器存在局限性(最著名的例子是无法解决异或问题),并且他提出的具体误差校正并非我们今天使用的通用反向传播,但 Rosenblatt 的工作为后来多层网络的发展奠定了基础。
与此同时,在控制理论和优化领域,研究人员正在开发基于链式法则计算梯度的方法。Henry J. Kelley 在 1960 年提出了一种方法,其中梯度通过表示控制过程的计算图反向传播。Stuart Dreyfus 在 1962 年发表了一个基于链式法则的更简单的推导。虽然当时这些方法并未直接应用于神经网络,但通过反向传播信息来有效计算导数的原理是现代反向传播的关键先驱。
然而,在 20 世纪 60 年代,神经网络领域仍处于起步阶段,并且缺乏有效实施复杂算法所需的计算资源。尽管如此,控制理论和优化领域的研究人员继续改进这些原理,最终促成了现代反向传播算法的形成。
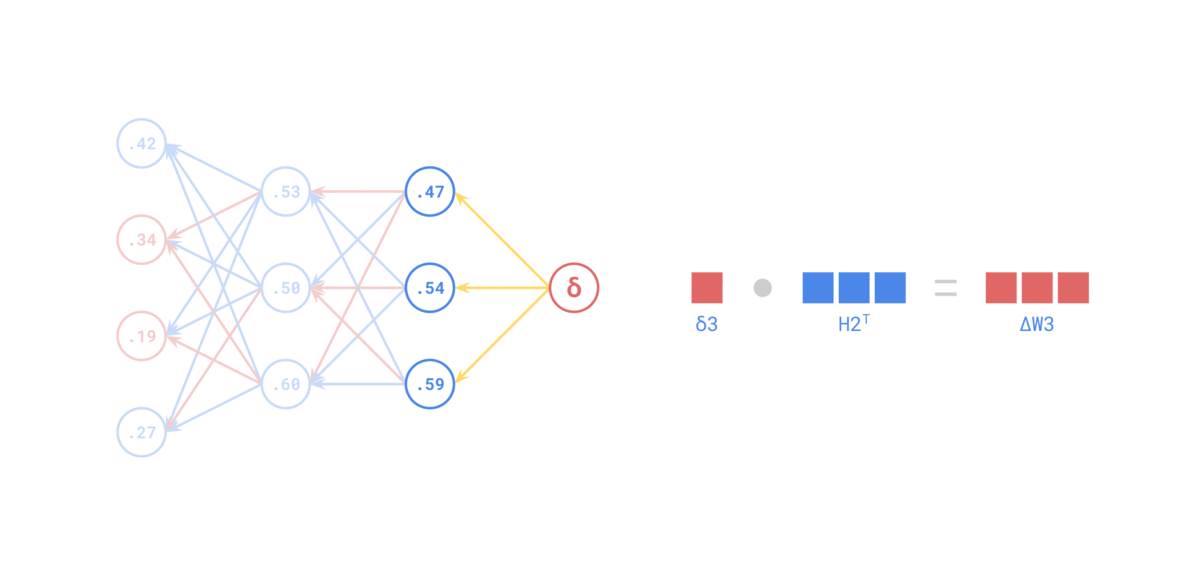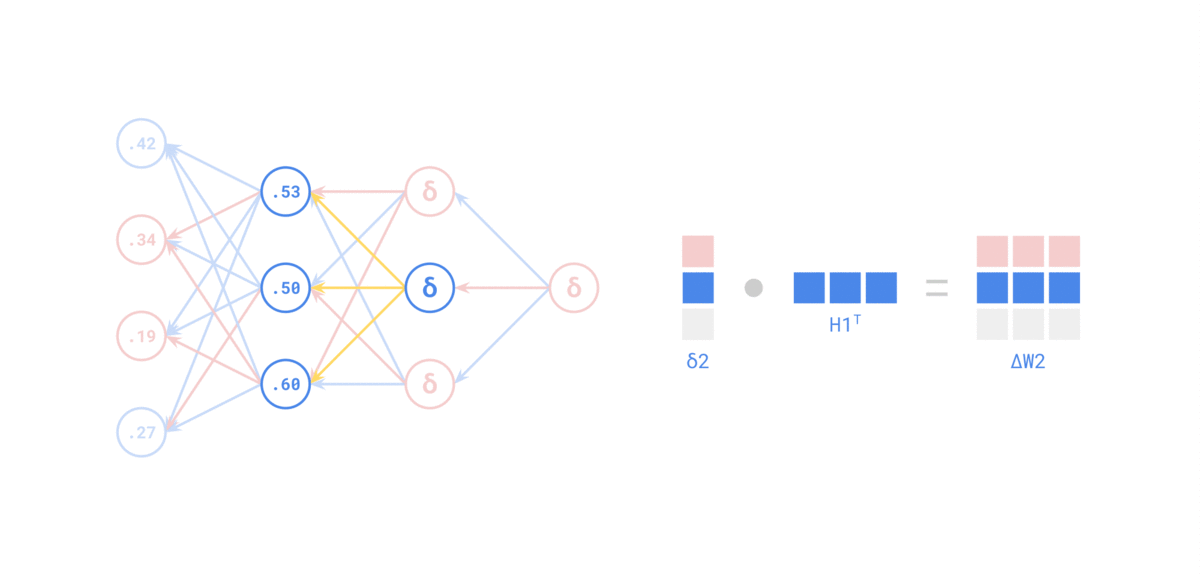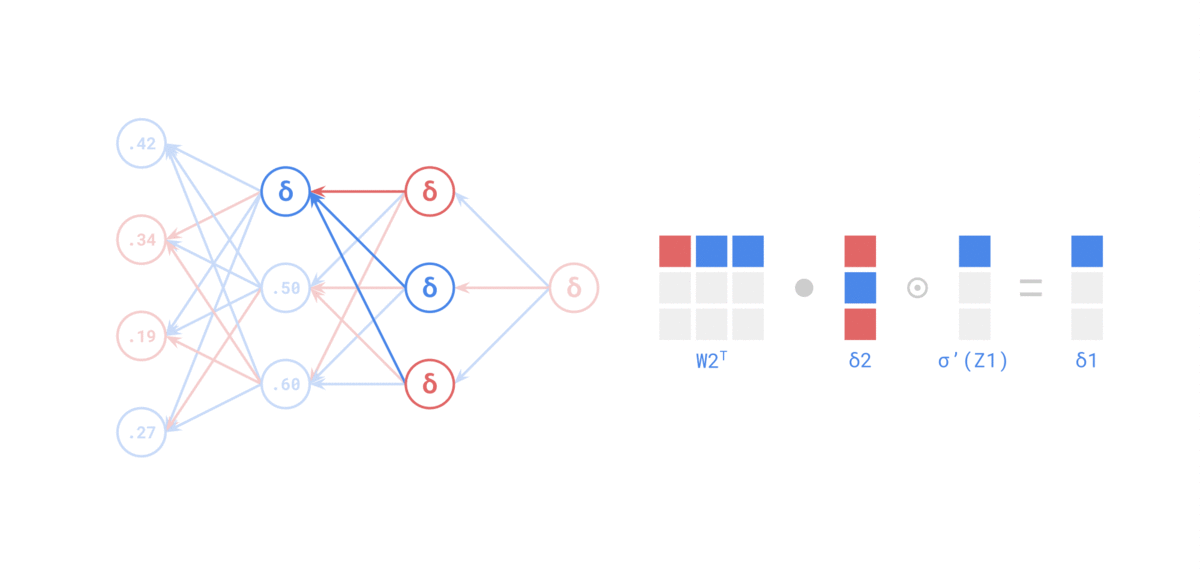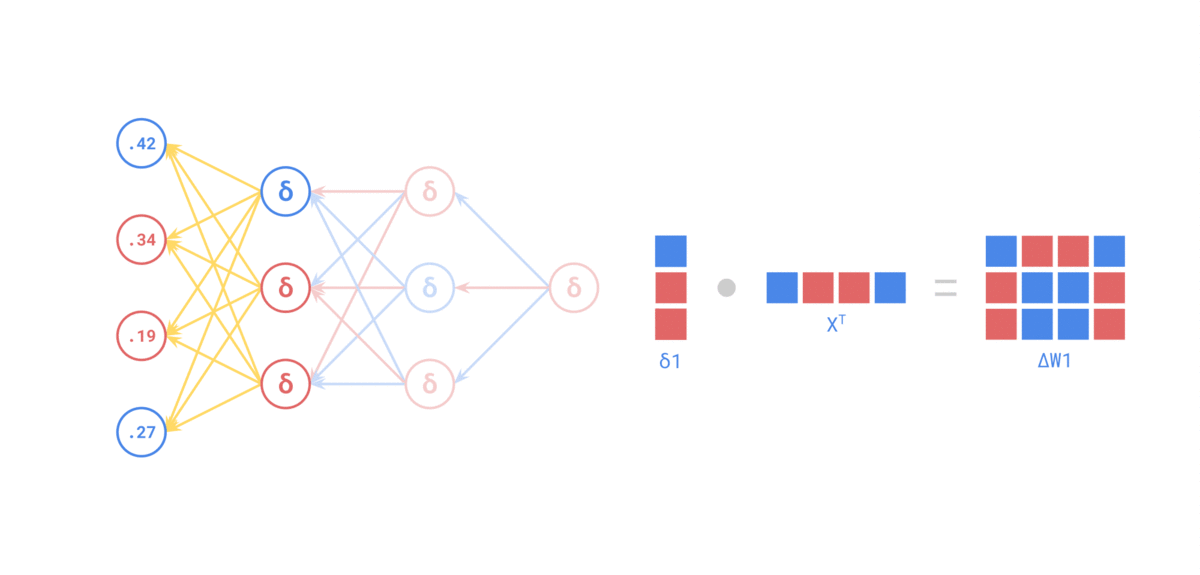
来源: https://medium.com/the-feynman-journal/what-makes-backpropagation-so-elegant-657f3afbbd
形式化和普及
现代高效的算法形式,即所谓的 反向模式自动微分,由芬兰研究员 Seppo Linnainmaa 在他 1970 年的硕士论文(1976 年出版)中进行了严格描述。Linnainmaa 开发了这种通用方法,用于有效计算复杂嵌套函数的导数,这构成了当今反向传播的数学核心。然而,Linnainmaa 的工作并未关注神经网络。
Paul Werbos 在他 1974 年的博士论文(后来出版)中明确指出了与神经网络的关键联系。Werbos 认识到 Linnainmaa 的反向模式自动微分可以应用于训练多层人工神经网络。他首先演示了该算法如何有效地调整多层感知器 (MLP) 中的权重,克服了单层感知器的局限性,并使网络能够学习复杂的模式。Werbos 的工作是人工智能领域的一项突破,为未来神经网络的进步铺平了道路。
尽管取得了这些进展,但反向传播算法直到 20 世纪 80 年代中期才获得广泛关注。1986 年,David E. Rumelhart、Geoffrey Hinton 和 Ronald J. Williams 发表了他们的开创性论文《通过反向传播误差进行表征学习》。这篇论文清楚地展示了反向传播在训练各种问题上的 MLP 方面的实际威力。这项研究至关重要,因为它令人信服地表明,人工神经网络可以学习有用的内部表征,并解决以前认为对它们来说难以处理的复杂任务。该论文不仅在普及该算法方面发挥了关键作用,而且还重振了对神经网络的研究,神经网络在此前的“人工智能寒冬”中面临着质疑。
这篇里程碑式的论文重新点燃了人工智能研究界对人工神经网络的兴趣。由于反向传播的效率,多层网络变得可以有效地训练,为深度学习革命和现代人工智能的重大突破打开了大门。
来源: https://medium.com/the-feynman-journal/what-makes-backpropagation-so-elegant-657f3afbbd
实际应用:Yann LeCun 的突破
尽管反向传播的理论基础在 20 世纪 60 年代和 70 年代就已奠定,但其第一个真正具有影响力的实际应用出现在 20 世纪 80 年代后期。Yann LeCun,现在被公认为人工智能的先驱之一,在 1989 年于贝尔实验室工作期间,展示了将反向传播与 卷积神经网络 (CNN) 相结合的力量。LeCun 和他的同事将使用反向传播训练的 CNN 应用于 手写数字识别 任务。
这项革命性的应用促成了一个能够自动读取支票上手写数字的系统的开发。LeCun 的工作不仅证明了反向传播可以解决复杂的现实世界问题,还表明神经网络,特别是 CNN 架构,对于计算机视觉任务非常有效。这一突破标志着人工智能新时代的开始,为神经网络和反向传播在众多工业和研究应用中的广泛使用铺平了道路。
LeCun 的工作尤其重要,因为 CNN 非常适合处理视觉数据,因为它们可以捕获图像中的空间层次结构。反向传播使这些网络能够学习适当的滤波器权重,以最大限度地减少分类误差,从而能够从图像数据中有效提取有意义的特征。
此后,Yann LeCun 的名字已成为 CNN 和深度学习的代名词。2018 年,他与 Geoffrey Hinton 和 Yoshua Bengio 一起获得了计算机领域的最高荣誉 图灵奖,以表彰他们对深度学习的奠基性贡献。LeCun 的工作为反向传播理论与强大的实际应用之间架起了一座至关重要的桥梁,为人工智能开辟了新的视野。
来源: https://medium.com/the-feynman-journal/what-makes-backpropagation-so-elegant-657f3afbbd
反向传播的挑战与演变
尽管反向传播被广泛采用并证明了其效用,但并非没有挑战,特别是当研究人员开始构建更深的网络时。出现了两个重大问题:梯度消失 和 梯度爆炸 问题。
梯度消失问题
当误差信号从输出层向较早层反向传播时呈指数级减小时,深度网络中就会出现梯度消失。在反向传播期间,梯度是使用链式法则计算的,这涉及将许多小数字(激活函数的导数,通常小于 1)相乘。在深度网络中,这种重复乘法可能导致梯度变得非常小,实际上是“消失”了。因此,较早层中的权重不会显着更新,从而阻碍学习过程。这对训练非常深的神经网络构成了主要障碍。
梯度爆炸问题
相反,当梯度在反向传播期间呈指数级增长时,就会发生梯度爆炸。如果权重或导数很大,则可能会发生这种情况,从而导致权重的巨大更新。网络的权重可能会迅速发散到极端值(如 NaN - 非数字),导致不稳定并使网络无法学习。
解决方案和增强功能
多年来,研究人员开发了许多技术来缓解这些梯度问题。主要解决方案包括:
- 更好的激活函数: 用 ReLU(修正线性单元)等函数替换 sigmoid/tanh 有助于缓解梯度消失,因为 ReLU 的正输入导数为 1。
- 权重初始化方案: 仔细初始化权重(例如,Xavier/Glorot 或 He 初始化)有助于将梯度保持在合理的范围内。
- 批量归一化: 这项技术对中间层中的激活进行归一化,从而稳定网络并允许更高的学习率,这间接有助于解决梯度问题。
- 残差连接 (ResNet): 在残差网络中引入的这些“跳跃连接”允许梯度通过绕过某些层更容易地流经网络,从而有效地对抗非常深层架构中的梯度消失问题。
- 梯度裁剪: 一种简单的技术,通过限制梯度值(如果它们超过某个阈值)来防止梯度爆炸。
- 高级优化算法: 诸如 Adam、RMSProp 和 AdaGrad 之类的优化器会调整每个参数的学习率,与标准随机梯度下降 (SGD) 相比,通常可以更快地收敛并更好地处理具有挑战性的梯度环境。
反向传播的今日作用
反向传播仍然是深度学习领域中最关键的算法之一。尽管出现了许多变体和替代方法,但反向传播(以其各种形式,通常与上述技术相结合)仍然是训练绝大多数神经网络的主力。现代人工神经网络已经发展成为极其复杂的模型,能够解决人工智能领域一些最具挑战性的问题,包括计算机视觉、自然语言处理 (NLP) 和自动驾驶。反向传播算法推动了这些先进技术的发展,并将继续成为机器学习的基石。





