Los 86 mil millones de neuronas de nuestro cerebro: ¿Pueden superarlas los LLM?
El cerebro humano, un complejo sistema biológico perfeccionado a lo largo de millones de años de evolución, contrasta con los Modelos de Lenguaje Grandes (LLM), los últimos logros en inteligencia artificial. Aunque los LLM demuestran capacidades impresionantes en el procesamiento del lenguaje, ¿podrán alguna vez superar la complejidad y las habilidades del cerebro humano?

El cerebro humano se considera a menudo el más avanzado cognitivamente entre los mamíferos, y su tamaño parece significativamente mayor de lo que predeciría nuestro tamaño corporal. Generalmente se acepta que el número de neuronas desempeña un papel clave en la capacidad computacional del cerebro, pero la afirmación común de que el cerebro humano contiene 100.000 millones de neuronas y diez veces más células gliales nunca se ha confirmado científicamente. De hecho, el número preciso de neuronas y células gliales en el cerebro humano era desconocido hasta hace poco.
Según los últimos hallazgos, un cerebro adulto masculino medio contiene 86.1 ± 8.100 millones de neuronas y 84.6 ± 9.800 millones de células no neuronales (glía). Curiosamente, sólo el 19% de las neuronas se encuentran en la corteza cerebral, a pesar de que la corteza representa el 82% de la masa del cerebro humano. Esto significa que el aumento de tamaño de la corteza humana no va acompañado de un aumento proporcional del número de neuronas corticales.
La proporción de células gliales con respecto a las neuronas en diferentes regiones del cerebro humano es similar a la observada en otros primates, y el recuento total de células se alinea con los valores esperados para un primate de tamaño humano. Estos resultados desafían la opinión generalizada de que el cerebro humano tiene una composición especial en comparación con otros primates. En cambio, sugieren que el cerebro humano es una versión a escala isométrica de un cerebro de primate medio, esencialmente, un cerebro de primate adaptado al tamaño humano.
Esta constatación ofrece una nueva perspectiva, que nos incita a reconsiderar qué es lo que realmente hace únicos el pensamiento humano y las capacidades cognitivas. Hoy, sin embargo, abordo la cuestión desde un ángulo diferente: ¿se puede comparar nuestro cerebro con los Modelos de Lenguaje Grandes (LLM), por ejemplo, en términos de número de parámetros? O, a pesar de que los investigadores y desarrolladores de IA estudian continuamente nuestro cerebro e intentan traducir su funcionamiento en sistemas de inteligencia artificial, ¿carece de sentido cualquier comparación, simplemente porque uno es un sistema químico y el otro electrónico? Pero primero, algunos antecedentes relacionados.
¿Cómo se cuentan las neuronas?
Estimar el número de neuronas es una tarea complicada, ya que el cerebro no tiene una estructura uniforme. Un método consiste en contar las neuronas en una región cerebral específica y luego extrapolar este valor a todo el cerebro. Sin embargo, este método plantea varios problemas:
-
Distribución desigual
La densidad de neuronas varía mucho entre las diferentes partes del cerebro. Por ejemplo, el cerebelo, situado en la parte inferior trasera del cerebro, contiene aproximadamente la mitad de todas las neuronas, a pesar de tener un volumen significativamente menor en comparación con el resto del cerebro. Esto se debe a que las diminutas neuronas del cerebelo son responsables de afinar la coordinación motora y otros procesos automatizados. La corteza cerebral mencionada anteriormente, responsable del pensamiento de orden superior, contiene neuronas más grandes que forman redes más complejas. Aquí, un milímetro cúbico contiene aproximadamente 50.000 neuronas. -
Visibilidad de las neuronas
Las neuronas están tan densamente empaquetadas e intrincadamente interconectadas que contarlas individualmente es difícil. Una solución clásica es la tinción de Golgi, desarrollada por Camillo Golgi. Esta técnica tiñe sólo una pequeña fracción de neuronas (normalmente un pequeño porcentaje), dejando invisibles otras células. Aunque esto ayuda a obtener una muestra más detallada, la extrapolación de los resultados sigue conllevando incertidumbres.
La última estimación, más precisa, se basa en una técnica innovadora. Los investigadores disuelven las membranas de las células cerebrales, creando una mezcla homogénea, una especie de "sopa de cerebro", donde se pueden distinguir los núcleos de las células cerebrales. La tinción de estos núcleos con diferentes marcadores permite separar las neuronas de otras células cerebrales, como la glía. Este método, a menudo denominado técnica del fraccionador isotrópico, elimina los errores derivados de las diferencias de densidad entre las regiones cerebrales y proporciona un resultado más preciso para todo el cerebro.
Aunque esta nueva tecnología reduce significativamente la incertidumbre de las estimaciones anteriores, el método sigue basándose en el muestreo y la extrapolación.
¿Cómo funciona el cerebro humano?
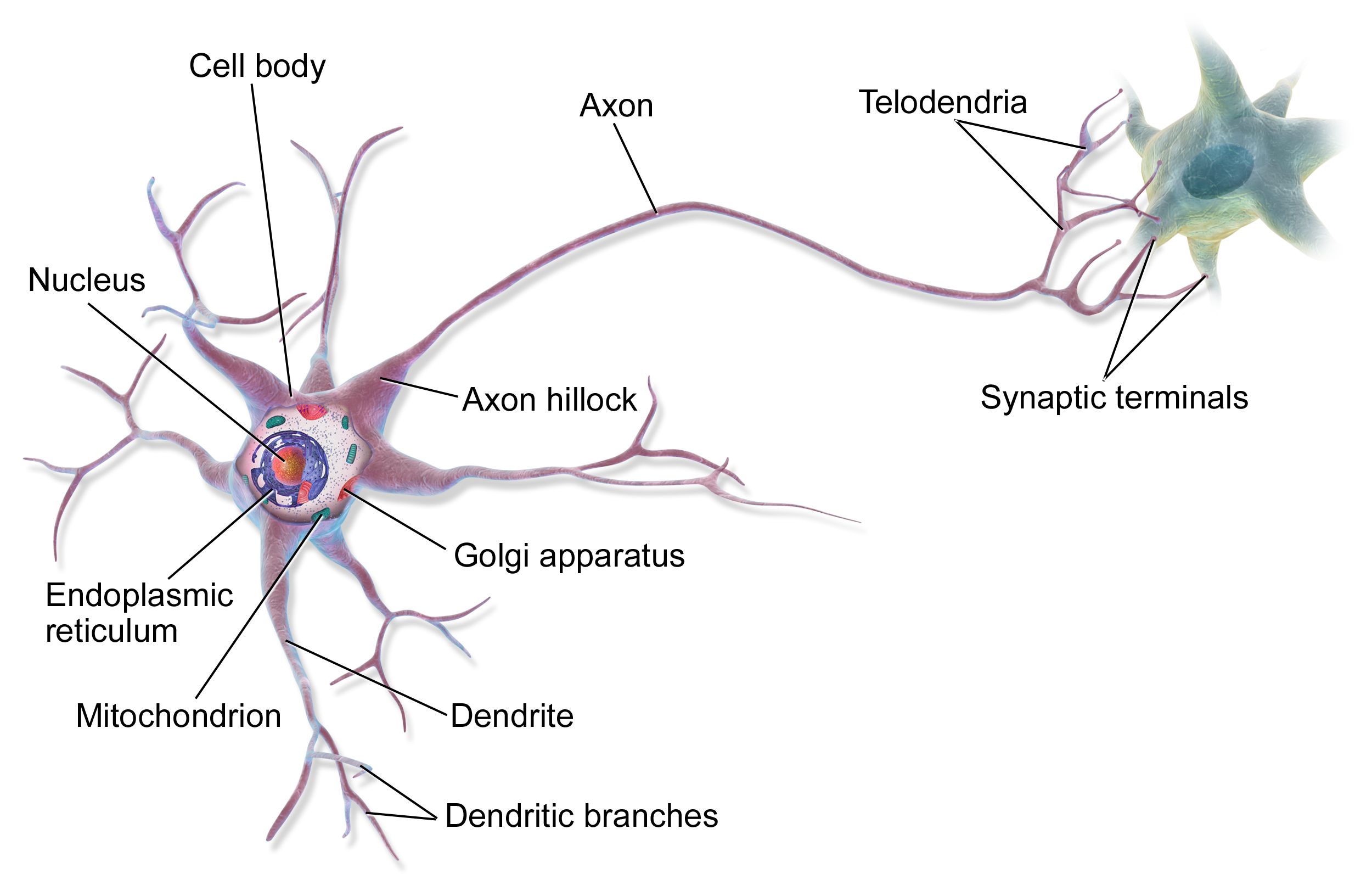
Los componentes fundamentales del cerebro son las neuronas, de las que ahora sabemos que hay unos 86.000 millones en un cerebro adulto. Sin embargo, no todas son iguales: existen muchos tipos diferentes de neuronas que realizan funciones distintas. Junto a las neuronas, hay aproximadamente el mismo número de células gliales, que proporcionan funciones de apoyo, como el suministro de nutrientes y la participación en la defensa inmunitaria.
Las conexiones entre las neuronas, las sinapsis, son lo que hace que el cerebro sea realmente especial. Una neurona media forma unas 7.000 sinapsis con otras neuronas, lo que da como resultado un total de aproximadamente 600-1000 billones de conexiones sinápticas en el cerebro. Estas conexiones no son estáticas, sino que cambian constantemente, fortaleciéndose o debilitándose durante los procesos de aprendizaje. Esto se conoce como plasticidad sináptica.
Fuente: Wikipedia
Las diferentes regiones del cerebro están especializadas en funciones específicas (como se ha mencionado anteriormente). El cerebro es el centro del pensamiento consciente, la percepción y la planificación motora. El cerebelo es la principal zona de coordinación motora y aprendizaje procedimental. El tronco encefálico regula las funciones vitales básicas, mientras que el sistema límbico es responsable del procesamiento emocional y la memoria.
El procesamiento de la información en el cerebro se produce en paralelo: diferentes regiones trabajan en diferentes tareas simultáneamente. La información se transmite mediante una combinación de señales eléctricas y químicas. Cuando una neurona se activa, envía un impulso eléctrico (potencial de acción) por su axón, lo que desencadena la liberación de neurotransmisores en las sinapsis. Estos mensajeros químicos influyen entonces en la actividad de la siguiente neurona.
El consumo de energía del cerebro es notablemente eficiente: utiliza sólo unos 20 vatios, el equivalente a la potencia de una bombilla de bajo consumo. A pesar de ello, el cerebro consume aproximadamente el 20% del gasto energético total del organismo (aunque sólo representa el 2% de nuestra masa corporal), lo que indica lo intensivo en energía que es el procesamiento de la información.
La actividad cerebral se organiza no sólo a nivel neuronal. Se pueden observar diferentes ondas cerebrales de frecuencia (alfa, beta, theta, delta), que reflejan la actividad sincronizada de grandes grupos de neuronas. Estos ritmos desempeñan funciones importantes, por ejemplo, en la consolidación de la memoria y los procesos de atención.
Una de las propiedades más importantes del cerebro es su plasticidad: su capacidad para reorganizarse a lo largo de la vida. Esta no es sólo la base del aprendizaje, sino que también permite una recuperación parcial tras una lesión. La neuroplasticidad se produce a través de diversos mecanismos, como la formación de nuevas sinapsis, el fortalecimiento o debilitamiento de las conexiones existentes y, en algunos casos, incluso la formación de nuevas neuronas (neurogénesis).
La investigación moderna demuestra que el cerebro no sólo está conectado al sistema nervioso central, sino que también interactúa estrechamente con el intestino (el eje intestino-cerebro) y está significativamente influenciado por el sistema inmunitario. Esta compleja red de interacciones explica por qué factores como la dieta o el estrés tienen un impacto tan profundo en las funciones cognitivas.
La ciencia aún se enfrenta a muchas preguntas sobre el funcionamiento del cerebro. Por ejemplo, aún no entendemos cómo surge la conciencia ni cómo se almacenan y recuperan exactamente los recuerdos. Los proyectos de investigación cerebral a gran escala en curso, como el Proyecto Cerebro Humano o la Iniciativa BRAIN, prometen nuevos descubrimientos en un futuro próximo.
¿Cómo funcionan los modelos lingüísticos?
Si bien la arquitectura fundamental de los cerebros humanos es similar, con variaciones individuales observadas en la estructura y la función (debido a factores como la neurodiversidad o las experiencias individuales), los modelos lingüísticos de inteligencia artificial exhiben un amplio espectro en términos de estructura y parámetros. Estas diferencias de modelo pueden surgir del uso de diferentes arquitecturas (como transformadores frente a redes recurrentes) o de ser entrenados con diferentes conjuntos de datos. Sin embargo, hay algunas áreas en las que están más o menos alineados. Intentaré esbozar éstas.
Los modelos lingüísticos basados en transformadores (como los modelos GPT o Llama) se construyen fundamentalmente a partir de bloques (capas) de transformadores, que contienen partes de codificador y decodificador (o a menudo sólo partes de decodificador). Cada bloque alberga varios componentes que realizan diferentes tareas. Los más importantes entre ellos son el mecanismo de autoatención multicabezal y la capa de red neuronal de avance. Además de estos componentes, la normalización de capas, el dropout y la codificación posicional también desempeñan un papel importante. La esencia del mecanismo de autoatención es que aprende dinámicamente las relaciones entre las palabras de entrada, mientras que la red de avance realiza una transformación no lineal.
Cuando hablamos del número de parámetros (uno de los determinantes más cruciales de los modelos lingüísticos, a menudo incluso incluido en el nombre del modelo), en realidad nos referimos a la suma de los pesos y sesgos aprendibles del modelo. Estos parámetros determinan cómo procesa la información el modelo y se optimizan durante el entrenamiento (proceso de aprendizaje). El número de parámetros depende de varios factores:
-
Número de bloques de transformadores: Los modelos más grandes suelen contener más bloques de transformadores. Por ejemplo, los 175.000 millones de parámetros de GPT-3 [^1] utilizan 96 bloques (capas), mientras que la versión de 70.000 millones de parámetros de Llama 2 utiliza 80 bloques. La profundidad de los bloques influye significativamente en el número de parámetros.
-
Tamaño del estado oculto: Se trata de un vector que representa la información dentro de un bloque dado y determina cuánta información puede procesar simultáneamente el modelo. Cuanto mayor sea este número, más parámetros se necesitan en los bloques de transformadores.
-
Número de cabezales de atención: La atención multicabezal permite al modelo analizar la misma entrada desde diferentes perspectivas. Cada cabezal de atención requiere parámetros adicionales.
Observando cifras concretas: en un bloque transformador típico, los parámetros se distribuyen entre:
-
Las matrices de pesos del mecanismo de atención (matrices Query, Key, Value)
-
Los pesos y sesgos de la red de avance
-
Los parámetros de escalado y desplazamiento de la normalización de capas
-
Parámetros para la codificación posicional (tanto para las versiones aprendidas como para las sinusoidales)
Un aspecto interesante es la complejidad computacional: el coste computacional del mecanismo de autoatención crece cuadráticamente con la longitud de la secuencia. Esto significa que, aunque el modelo tenga muchos parámetros, no todos los parámetros están activos simultáneamente durante el procesamiento real. Las técnicas de atención dispersa intentan abordar este problema.
Por lo tanto, el número de parámetros por sí solo no es necesariamente una buena medida de las capacidades de un modelo. Un modelo más pequeño con una arquitectura mejor a menudo puede superar a un modelo más grande pero menos eficiente. El rendimiento del modelo también se evalúa utilizando métricas como la precisión, la puntuación F1, la puntuación BLEU o la PERPLEJIDAD. Esto es similar a como en el cerebro humano, no es sólo el número de neuronas o sinapsis lo que importa, sino también su organización y la calidad de las conexiones entre ellas.
¿Se puede comparar el cerebro con un modelo lingüístico basándose en valores específicos?
Aunque podría ser tentador calibrar el nivel actual de inteligencia artificial comparando su rendimiento y conocimiento con nuestro cerebro, las descripciones anteriores sugieren que, aunque la principal fuente para desarrollar sistemas artificiales es el estudio de la estructura y función de nuestro cerebro (ya que es un ejemplo funcional -por trivial que parezca, es un hecho crucial-), la comparación dista mucho de ser sencilla. Comparar directamente los parámetros de los LLM con el número de neuronas o sinapsis no es factible porque los dos sistemas se basan en principios de funcionamiento y arquitecturas fundamentalmente diferentes. Sin embargo, a pesar de las diferencias fundamentales, se pueden establecer algunas analogías entre ambos sistemas.
Neuronas vs. Capas LLM
-
Las capas LLM se parecen en cierto modo a la estructura jerárquica del cerebro, donde el procesamiento de la información se produce en múltiples niveles. Sin embargo, en el cerebro, la jerarquía es más funcional y está dividida en regiones especializadas, mientras que en los LLM, las capas representan niveles de abstracción.
-
Las neuronas son unidades localmente independientes pero globalmente organizadas en redes, mientras que las capas LLM son globalmente interdependientes a través del mecanismo de atención. La autoatención permite el flujo global de información dentro de una capa.
Sinapsis vs. Parámetros LLM
-
Los parámetros LLM son similares a las sinapsis en el sentido de que ambos influyen en la fuerza del flujo de información, aunque a través de mecanismos diferentes.
-
Las sinapsis cambian dinámicamente y se adaptan, mientras que los parámetros LLM son estáticos después del entrenamiento. El ajuste fino permite que los parámetros vuelvan a cambiar, pero esto todavía no coincide con la naturaleza dinámica de las sinapsis. La fuerza sináptica cambia a través de la potenciación a largo plazo (PLP) o la depresión a largo plazo (DLP), que son procesos bio-electroquímicos dinámicos.
¿Qué representa mejor los parámetros LLM?
-
Ni las neuronas ni las sinapsis representan con precisión los parámetros LLM, pero la analogía más cercana es con las sinapsis, ya que también regulan las conexiones y la fuerza del flujo de información. Utilizando este enfoque, es interesante observar que el número de sinapsis en el cerebro es órdenes de magnitud mayor (100-1000 billones de sinapsis en comparación con 70.000 millones a potencialmente más de 1 billón de parámetros en los LLM más grandes).
-
Sin embargo, las sinapsis son mucho más complejas y dinámicas que los parámetros LLM. Las sinapsis no son sólo pesos simples; regulan las conexiones a través de complejos procesos bio-electroquímicos que cambian dinámicamente en función de la actividad y la experiencia.
¿Por qué es imprecisa la analogía?
-
Diferencias operativas:
-
El cerebro exhibe paralelismo biológico y procesa señales continuas, mientras que los LLM se basan en computaciones digitales discretas realizadas por procesadores numéricos (GPU/TPU). En el cerebro, los cálculos se llevan a cabo mediante procesos bioquímicos y señales eléctricas.
-
-
Mecanismo de aprendizaje:
-
El aprendizaje cerebral es dinámico y eficiente incluso con pocos datos. El reconocimiento de patrones y el refuerzo desempeñan un papel crucial. El aprendizaje humano suele ser de una sola vez o de pocas veces, lo que permite generalizar a partir de pocos ejemplos. El aprendizaje por refuerzo también es importante en el cerebro.
-
El entrenamiento de los LLM requiere enormes cantidades de datos y recursos computacionales. Los LLM son menos capaces de generalizar a partir de pocos ejemplos.
-
-
Eficiencia energética:
-
El cerebro es extremadamente eficiente energéticamente. El entrenamiento y el funcionamiento de los LLM son enormemente intensivos en energía, órdenes de magnitud superiores al consumo energético del cerebro humano.
-
-
Representación:
-
Las representaciones en el cerebro son distribuidas y dinámicas, mientras que en los LLM son más bien vectores estáticos.
-
El cerebro está asociado a la conciencia y la experiencia subjetiva, de las que actualmente carecen los LLM.
-
-
Arquitectura:
-
La organización jerárquica del cerebro es mucho más compleja y modular, con diferentes regiones que realizan diferentes funciones. Esta modularidad es menos pronunciada en los LLM.
-
Los bucles de retroalimentación desempeñan un papel importante en el cerebro, mientras que esto es menos característico de la mayoría de los LLM.
-
-
Adaptación y flexibilidad:
-
El cerebro es muy adaptable y flexible debido a la neuroplasticidad, mientras que los LLM son menos capaces de adaptarse a los cambios posteriores al entrenamiento.
-
El cerebro puede adaptarse a su entorno, una capacidad menos evidente en los LLM.
-
-
Emociones y motivación:
-
Las emociones desempeñan un papel vital en la toma de decisiones y el aprendizaje en el cerebro, una dimensión que falta en los LLM.
-
La motivación es crucial para el comportamiento en el cerebro, otra dimensión ausente en los LLM.
-
Resumen
Como hemos visto, aunque se pueden establecer ciertas analogías entre las capas LLM y la estructura jerárquica del cerebro, o entre los parámetros LLM y las sinapsis, estas analogías son limitadas. Por lo tanto, la pregunta planteada en el título del artículo, "Los 86 mil millones de neuronas de nuestro cerebro: ¿Pueden superarlas los LLM?" no tiene una respuesta directa.
Los dos sistemas se basan en principios de funcionamiento y arquitecturas fundamentalmente diferentes. Los LLM carecen de conciencia, experiencia subjetiva y no pueden generalizar a partir de pocos ejemplos de la forma en que puede hacerlo el cerebro.
Es probable que la futura investigación en inteligencia artificial se centre en seguir desarrollando las capacidades de los LLM, acercándolos potencialmente al funcionamiento del cerebro humano. Esto podría incluir el desarrollo de mecanismos de aprendizaje más dinámicos, una mayor eficiencia energética, mejores capacidades de generalización y quizás la implementación de alguna forma de conciencia. Una comprensión más profunda de la función cerebral podría ayudar a desarrollar sistemas de IA más eficientes e inteligentes.
Sin embargo, es importante recordar que los LLM no son copias del cerebro humano, sino que representan un camino diferente para alcanzar la inteligencia. Comprender las diferencias entre ambos sistemas es esencial para utilizar las oportunidades que ofrece la inteligencia artificial de forma responsable y eficaz. En el futuro, la sinergia entre la neurociencia y la inteligencia artificial podría abrir nuevos horizontes para ambos campos.
Fuentes:
- https://pubmed.ncbi.nlm.nih.gov/19226510/
- https://www.nature.com/scitable/blog/brain-metrics/are_there_really_as_many/
- https://www.sciencealert.com/scientists-quantified-the-speed-of-human-thought-and-its-a-big-surprise
- https://www.ndtv.com/science/human-brains-are-not-as-fast-as-we-previously-thought-study-reveals-7323078
- https://www.sciencealert.com/physics-study-overturns-a-100-year-old-assumption-on-how-brains-work
[^1]: Nota: Si bien 175B es la cifra ampliamente citada para el GPT-3 original, el número de parámetros para los modelos más nuevos o versiones específicas puede variar y a veces no se divulga oficialmente.





