Les 86 milliards de neurones de notre cerveau : les LLM peuvent-ils les surpasser ?
Le cerveau humain, un système biologique complexe perfectionné au cours de millions d'années d'évolution, contraste avec les Grands Modèles Linguistiques (LLM), les dernières avancées en matière d'intelligence artificielle. Bien que les LLM démontrent des capacités impressionnantes en traitement du langage, peuvent-ils un jour surpasser la complexité et les capacités du cerveau humain ?

Le cerveau humain est souvent considéré comme le plus avancé cognitivement parmi les mammifères, et sa taille apparaît significativement plus importante que ce que la taille de notre corps laisserait prévoir. Le nombre de neurones est généralement reconnu comme jouant un rôle clé dans la capacité de calcul du cerveau, mais l'affirmation courante selon laquelle le cerveau humain contiendrait 100 milliards de neurones et dix fois plus de cellules gliales n'a jamais été scientifiquement confirmée. En fait, le nombre précis de neurones et de cellules gliales dans le cerveau humain était inconnu jusqu'à récemment.
Selon les dernières découvertes, un cerveau d'homme adulte moyen contient 86,1 ± 8,1 milliards de neurones et 84,6 ± 9,8 milliards de cellules non neuronales (glie). Il est intéressant de noter que seulement 19 % des neurones sont situés dans le cortex cérébral, alors même que le cortex représente 82 % de la masse du cerveau humain. Cela signifie que l'augmentation de la taille du cortex humain ne s'accompagne pas d'une augmentation proportionnelle du nombre de neurones corticaux.
Le rapport entre les cellules gliales et les neurones dans différentes régions du cerveau humain est similaire à celui observé chez d'autres primates, et le nombre total de cellules correspond aux valeurs attendues pour un primate de taille humaine. Ces résultats remettent en question l'opinion largement répandue selon laquelle le cerveau humain aurait une composition spéciale par rapport aux autres primates. Au lieu de cela, ils suggèrent que le cerveau humain est une version à échelle isométrique d'un cerveau de primate moyen – essentiellement, un cerveau de primate adapté à la taille humaine.
Cette réalisation offre une nouvelle perspective, nous incitant à reconsidérer ce qui rend réellement uniques la pensée humaine et les capacités cognitives. Aujourd'hui, cependant, j'aborde la question sous un angle différent : notre cerveau peut-il être comparé aux Grands Modèles Linguistiques (LLM), par exemple, en termes de nombre de paramètres ? Ou bien, malgré le fait que les chercheurs et développeurs en IA étudient continuellement notre cerveau et essaient de traduire son fonctionnement en systèmes d'intelligence artificielle, toute comparaison est-elle dénuée de sens, simplement parce que l'un est un système chimique et l'autre un système électronique ? Mais d'abord, quelques informations de base connexes.
Comment les neurones sont-ils comptés ?
Estimer le nombre de neurones est une tâche délicate, car le cerveau n'a pas une structure uniforme. Une approche consiste à compter les neurones dans une région cérébrale spécifique, puis à extrapoler cette valeur à l'ensemble du cerveau. Cependant, cette méthode pose plusieurs problèmes :
-
Distribution inégale
La densité des neurones varie considérablement selon les différentes parties du cerveau. Par exemple, le cervelet, situé à la partie inférieure arrière du cerveau, contient environ la moitié de tous les neurones, bien qu'il ait un volume significativement plus petit par rapport au reste du cerveau. En effet, les minuscules neurones du cervelet sont responsables du réglage fin de la coordination motrice et d'autres processus automatisés. Le cortex cérébral mentionné précédemment – responsable de la pensée d'ordre supérieur – contient des neurones plus grands formant des réseaux plus complexes. Ici, un millimètre cube contient environ 50 000 neurones. -
Visibilité des neurones
Les neurones sont si densément entassés et intimement interconnectés qu'il est difficile de les compter individuellement. Une solution classique est la coloration de Golgi, développée par Camillo Golgi. Cette technique ne colore qu'une petite fraction des neurones (généralement quelques pour cent), laissant les autres cellules invisibles. Bien que cela permette d'obtenir un échantillon plus détaillé, l'extrapolation des résultats comporte toujours des incertitudes.
L'estimation la plus récente et la plus précise est basée sur une technique innovante. Les chercheurs dissolvent les membranes des cellules cérébrales, créant un mélange homogène – une sorte de « soupe de cerveau » – où les noyaux des cellules cérébrales peuvent être distingués. La coloration de ces noyaux avec différents marqueurs permet de séparer les neurones des autres cellules cérébrales, telles que les glies. Cette méthode, souvent appelée technique de fractionnement isotropique, élimine les erreurs dues aux différences de densité entre les régions cérébrales et fournit un résultat plus précis pour l'ensemble du cerveau.
Bien que cette nouvelle technologie réduise considérablement l'incertitude des estimations précédentes, la méthode repose toujours sur l'échantillonnage et l'extrapolation.
Comment fonctionne le cerveau humain ?
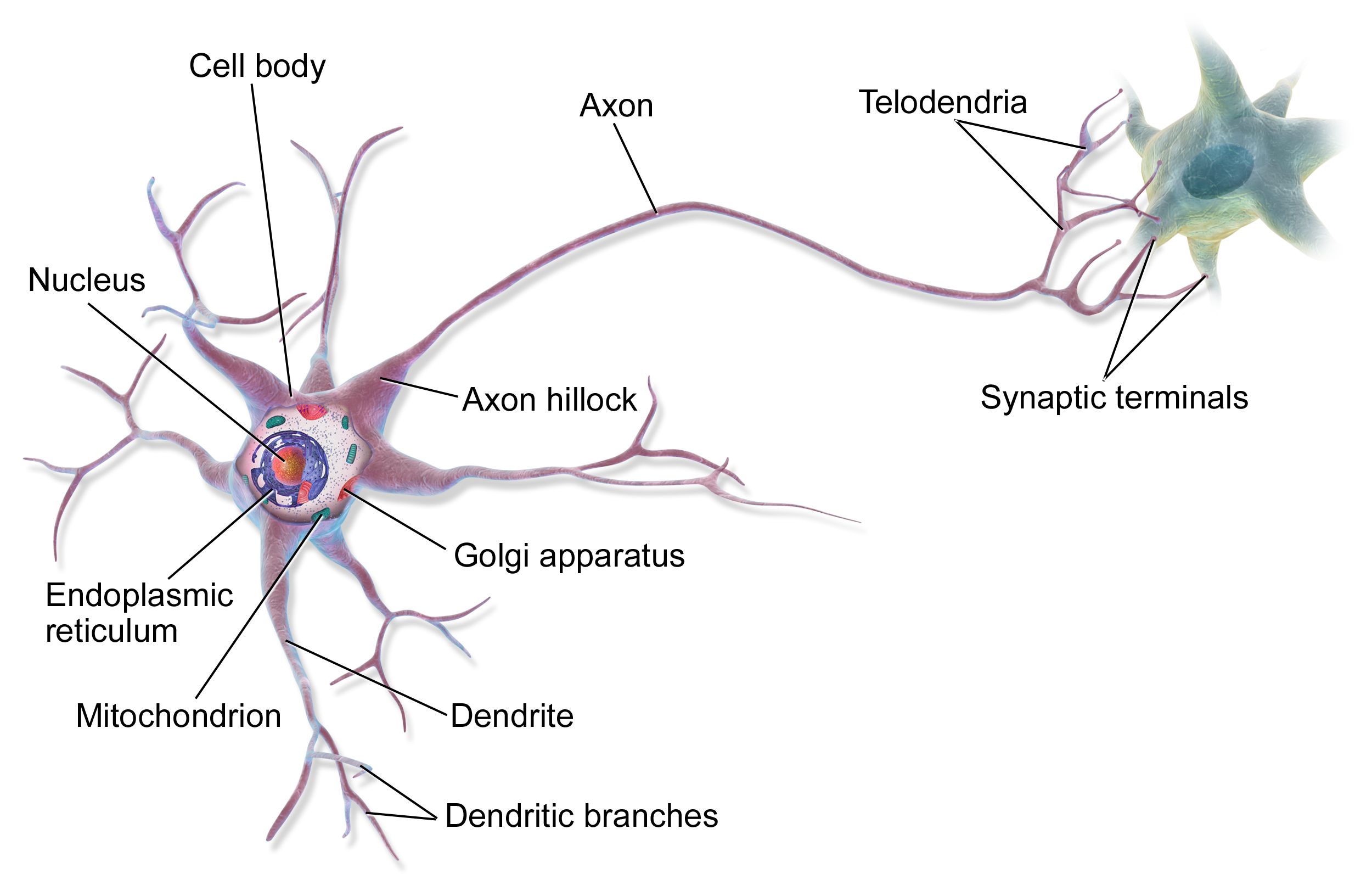
Les éléments constitutifs fondamentaux du cerveau sont les neurones, dont nous savons maintenant qu'ils sont environ 86 milliards dans un cerveau adulte. Cependant, ils ne sont pas tous identiques – il existe de nombreux types différents de neurones exerçant des fonctions distinctes. Parallèlement aux neurones, il existe à peu près le même nombre de cellules gliales, qui assurent des fonctions de soutien, telles que l'apport de nutriments et la participation à la défense immunitaire.
Les connexions entre les neurones, les synapses, sont ce qui rend le cerveau vraiment spécial. Un neurone moyen forme environ 7 000 synapses avec d'autres neurones, ce qui donne un total d'environ 600 à 1 000 billions de connexions synaptiques dans le cerveau. Ces connexions ne sont pas statiques – elles changent constamment, se renforçant ou s'affaiblissant pendant les processus d'apprentissage. C'est ce que l'on appelle la plasticité synaptique.
Source : Wikipédia
Différentes régions du cerveau sont spécialisées dans des fonctions spécifiques (comme nous l'avons évoqué précédemment). Le cerveau est le centre de la pensée consciente, de la perception et de la planification motrice. Le cervelet est la principale zone de coordination motrice et d'apprentissage procédural. Le tronc cérébral régule les fonctions vitales de base, tandis que le système limbique est responsable du traitement émotionnel et de la mémoire.
Le traitement de l'information dans le cerveau se fait en parallèle – différentes régions travaillent sur différentes tâches simultanément. L'information est transmise par une combinaison de signaux électriques et chimiques. Lorsqu'un neurone est activé, il envoie une impulsion électrique (potentiel d'action) le long de son axone, déclenchant la libération de neurotransmetteurs au niveau des synapses. Ces messagers chimiques influencent ensuite l'activité du neurone suivant.
La consommation d'énergie du cerveau est remarquablement efficace – il n'utilise qu'environ 20 watts, soit l'équivalent de la puissance d'une ampoule basse consommation. Malgré cela, le cerveau consomme environ 20 % de la dépense énergétique totale du corps (alors qu'il ne représente que 2 % de notre masse corporelle), ce qui indique à quel point le traitement de l'information est énergivore.
L'activité cérébrale n'est pas seulement organisée au niveau neuronal. Différentes ondes cérébrales de fréquence (alpha, bêta, thêta, delta) peuvent être observées, reflétant l'activité synchronisée de grands groupes de neurones. Ces rythmes jouent des rôles importants, par exemple, dans la consolidation de la mémoire et les processus attentionnels.
L'une des propriétés les plus cruciales du cerveau est sa plasticité – sa capacité à se réorganiser tout au long de la vie. C'est non seulement la base de l'apprentissage, mais cela permet également une récupération partielle après une blessure. La neuroplasticité se produit par divers mécanismes, tels que la formation de nouvelles synapses, le renforcement ou l'affaiblissement des connexions existantes et, dans certains cas, même la formation de nouveaux neurones (neurogenèse).
La recherche moderne montre que le cerveau n'est pas seulement connecté au système nerveux central, mais qu'il interagit également étroitement avec l'intestin (l'axe intestin-cerveau) et qu'il est significativement influencé par le système immunitaire. Ce réseau complexe d'interactions explique pourquoi des facteurs comme l'alimentation ou le stress ont un impact aussi profond sur les fonctions cognitives.
La science est encore confrontée à de nombreuses questions concernant le fonctionnement du cerveau. Par exemple, nous ne comprenons pas encore comment la conscience émerge ni précisément comment les souvenirs sont stockés et récupérés. Les projets de recherche sur le cerveau à grande échelle en cours, tels que le Human Brain Project ou la BRAIN Initiative, promettent de nouvelles découvertes dans un avenir proche.
Comment fonctionnent les modèles linguistiques ?
Alors que l'architecture fondamentale des cerveaux humains est similaire, avec des variations individuelles observées dans la structure et la fonction (en raison de facteurs tels que la neurodiversité ou les expériences individuelles), les modèles linguistiques d'intelligence artificielle présentent un large spectre en termes de structure et de paramètres. Ces différences de modèles peuvent provenir de l'utilisation de différentes architectures (comme les transformeurs par rapport aux réseaux récurrents) ou d'un entraînement sur différents ensembles de données. Cependant, il existe certains domaines où ils sont plus ou moins alignés. Je vais essayer de les décrire.
Les modèles linguistiques basés sur les transformeurs (comme les modèles GPT ou Llama) sont fondamentalement construits à partir de blocs de transformeurs (couches), qui contiennent des parties encodeur et décodeur (ou souvent juste des parties décodeur). Chaque bloc abrite plusieurs composants effectuant différentes tâches. Les plus importants d'entre eux sont le mécanisme d'auto-attention multi-têtes et la couche de réseau neuronal feed-forward. Outre ces composants, la normalisation des couches, le dropout et l'encodage de position jouent également un rôle important. L'essence du mécanisme d'auto-attention est qu'il apprend dynamiquement les relations entre les mots d'entrée, tandis que le réseau feed-forward effectue une transformation non linéaire.
Lorsque nous parlons du nombre de paramètres (l'un des déterminants les plus cruciaux des modèles linguistiques, souvent même inclus dans le nom du modèle), nous faisons en fait référence à la somme des poids et biais apprenables du modèle. Ces paramètres déterminent comment le modèle traite l'information et sont optimisés pendant le processus d'entraînement (apprentissage). Le nombre de paramètres dépend de plusieurs facteurs :
-
Nombre de blocs de transformeurs : Les modèles plus grands contiennent généralement plus de blocs de transformeurs. Par exemple, les 175 milliards de paramètres de GPT-3 [^1] utilisent 96 blocs (couches), tandis que la version Llama 2 à 70 milliards de paramètres utilise 80 blocs. La profondeur des blocs a un impact significatif sur le nombre de paramètres.
-
Taille de l'état caché : Il s'agit d'un vecteur représentant l'information au sein d'un bloc donné et qui détermine la quantité d'information que le modèle peut traiter simultanément. Plus ce nombre est élevé, plus il faut de paramètres dans les blocs de transformeurs.
-
Nombre de têtes d'attention : L'attention multi-têtes permet au modèle d'analyser la même entrée sous différents angles. Chaque tête d'attention nécessite des paramètres supplémentaires.
En examinant les chiffres spécifiques : dans un bloc de transformeur typique, les paramètres sont répartis entre :
-
Les matrices de poids du mécanisme d'attention (matrices Query, Key, Value)
-
Les poids et biais du réseau feed-forward
-
Les paramètres de mise à l'échelle et de décalage de la normalisation des couches
-
Les paramètres pour l'encodage de position (pour les versions apprises et sinusoïdales)
Un aspect intéressant est la complexité computationnelle : le coût computationnel du mécanisme d'auto-attention croît quadratiquement avec la longueur de la séquence. Cela signifie que bien que le modèle ait de nombreux paramètres, tous les paramètres ne sont pas actifs simultanément pendant le traitement réel. Les techniques d'attention clairsemée tentent de résoudre ce problème.
Par conséquent, le nombre de paramètres seul n'est pas nécessairement une bonne mesure des capacités d'un modèle. Un modèle plus petit avec une meilleure architecture peut souvent surpasser un modèle plus grand mais moins efficace. Les performances du modèle sont également évaluées à l'aide de mesures telles que la précision, le score F1, le score BLEU ou la PERPLEXITÉ. C'est similaire à la façon dont, dans le cerveau humain, ce n'est pas seulement le nombre de neurones ou de synapses qui compte, mais aussi leur organisation et la qualité des connexions entre eux.
Le cerveau peut-il être comparé à un modèle linguistique sur la base de valeurs spécifiques ?
Bien qu'il puisse être tentant d'évaluer le niveau actuel de l'intelligence artificielle en comparant ses performances et ses connaissances à notre cerveau, les descriptions ci-dessus suggèrent que bien que la source principale pour le développement de systèmes artificiels soit l'étude de la structure et de la fonction de notre cerveau (car c'est un exemple fonctionnel – aussi trivial que cela puisse paraître, c'est un fait crucial), la comparaison est loin d'être simple. Comparer directement les paramètres des LLM au nombre de neurones ou de synapses n'est pas réalisable car les deux systèmes sont basés sur des principes de fonctionnement et des architectures fondamentalement différents. Cependant, malgré les différences fondamentales, certaines analogies peuvent être établies entre les deux systèmes.
Neurones vs. Couches de LLM
-
Les couches de LLM ressemblent quelque peu à la structure hiérarchique du cerveau, où le traitement de l'information se produit à plusieurs niveaux. Cependant, dans le cerveau, la hiérarchie est plus fonctionnelle et divisée en régions spécialisées, tandis que dans les LLM, les couches représentent des niveaux d'abstraction.
-
Les neurones sont des unités localement indépendantes mais globalement organisées en réseaux, tandis que les couches de LLM sont globalement interdépendantes grâce au mécanisme d'attention. L'auto-attention permet un flux d'informations global au sein d'une couche.
Synapses vs. Paramètres de LLM
-
Les paramètres de LLM sont similaires aux synapses dans le sens où les deux influencent la force du flux d'informations, bien que par des mécanismes différents.
-
Les synapses changent dynamiquement et s'adaptent, tandis que les paramètres de LLM sont statiques après l'entraînement. Le fine-tuning permet aux paramètres de changer à nouveau, mais cela ne correspond toujours pas à la nature dynamique des synapses. La force synaptique change via la potentialisation à long terme (PLT) ou la dépression à long terme (DLT), qui sont des processus bio-électrochimiques dynamiques.
Qu'est-ce qui représente le mieux les paramètres de LLM ?
-
Ni les neurones ni les synapses ne représentent précisément les paramètres de LLM, mais l'analogie la plus proche est celle des synapses, car elles régulent également les connexions et la force du flux d'informations. En utilisant cette approche, il est intéressant de noter que le nombre de synapses dans le cerveau est de plusieurs ordres de grandeur supérieur (100 à 1 000 billions de synapses contre 70 milliards à potentiellement plus de 1 billion de paramètres dans les plus grands LLM).
-
Cependant, les synapses sont beaucoup plus complexes et dynamiques que les paramètres de LLM. Les synapses ne sont pas de simples poids ; elles régulent les connexions par des processus bio-électrochimiques complexes qui changent dynamiquement en fonction de l'activité et de l'expérience.
Pourquoi l'analogie est-elle imprécise ?
-
Différences opérationnelles :
-
Le cerveau présente un parallélisme biologique et traite des signaux continus, tandis que les LLM reposent sur des calculs numériques discrets, numériques, effectués par des processeurs numériques (GPU/TPU). Dans le cerveau, les calculs sont effectués par des processus biochimiques et des signaux électriques.
-
-
Mécanisme d'apprentissage :
-
L'apprentissage du cerveau est dynamique et efficace même avec peu de données. La reconnaissance de formes et le renforcement jouent des rôles cruciaux. L'apprentissage humain est souvent ponctuel ou à quelques reprises, permettant la généralisation à partir de quelques exemples. L'apprentissage par renforcement est également important dans le cerveau.
-
L'entraînement des LLM nécessite des quantités massives de données et de ressources computationnelles. Les LLM sont moins capables de généraliser à partir de quelques exemples.
-
-
Efficacité énergétique :
-
Le cerveau est extrêmement économe en énergie. L'entraînement et l'exécution des LLM sont extrêmement énergivores, de plusieurs ordres de grandeur supérieurs à la consommation d'énergie du cerveau humain.
-
-
Représentation :
-
Les représentations dans le cerveau sont distribuées et dynamiques, tandis que dans les LLM, elles ressemblent davantage à des vecteurs statiques.
-
Le cerveau est associé à la conscience et à l'expérience subjective, ce qui manque actuellement aux LLM.
-
-
Architecture :
-
L'organisation hiérarchique du cerveau est beaucoup plus complexe et modulaire, avec différentes régions exerçant différentes fonctions. Cette modularité est moins prononcée dans les LLM.
-
Les boucles de rétroaction jouent un rôle important dans le cerveau, alors que c'est moins caractéristique de la plupart des LLM.
-
-
Adaptation et flexibilité :
-
Le cerveau est très adaptable et flexible grâce à la neuroplasticité, tandis que les LLM sont moins capables de s'adapter aux changements après l'entraînement.
-
Le cerveau peut s'adapter à son environnement, une capacité moins évidente chez les LLM.
-
-
Émotions et motivation :
-
Les émotions jouent un rôle vital dans la prise de décision et l'apprentissage dans le cerveau, une dimension absente des LLM.
-
La motivation est cruciale pour le comportement dans le cerveau, une autre dimension absente des LLM.
-
Résumé
Comme nous l'avons vu, bien que certaines analogies puissent être établies entre les couches de LLM et la structure hiérarchique du cerveau, ou entre les paramètres de LLM et les synapses, ces analogies sont limitées. Ainsi, la question posée dans le titre de l'article, « Les 86 milliards de neurones de notre cerveau : les LLM peuvent-ils les surpasser ? », n'a pas de réponse simple.
Les deux systèmes sont basés sur des principes de fonctionnement et des architectures fondamentalement différents. Les LLM manquent de conscience, d'expérience subjective et ne peuvent pas généraliser à partir de quelques exemples de la manière dont le cerveau le peut.
La future recherche en intelligence artificielle se concentrera probablement sur le développement des capacités des LLM, les rapprochant potentiellement du fonctionnement du cerveau humain. Cela pourrait inclure le développement de mécanismes d'apprentissage plus dynamiques, une plus grande efficacité énergétique, de meilleures capacités de généralisation et peut-être la mise en œuvre d'une forme de conscience. Une compréhension plus approfondie de la fonction cérébrale pourrait aider à développer des systèmes d'IA plus efficaces et intelligents.
Cependant, il est important de se rappeler que les LLM ne sont pas des copies du cerveau humain, mais représentent une voie différente pour atteindre l'intelligence. Comprendre les différences entre les deux systèmes est essentiel pour utiliser les opportunités offertes par l'intelligence artificielle de manière responsable et efficace. À l'avenir, la synergie entre les neurosciences et l'intelligence artificielle pourrait ouvrir de nouveaux horizons pour les deux domaines.
Sources :
- https://pubmed.ncbi.nlm.nih.gov/19226510/
- https://www.nature.com/scitable/blog/brain-metrics/are_there_really_as_many/
- https://www.sciencealert.com/scientists-quantified-the-speed-of-human-thought-and-its-a-big-surprise
- https://www.ndtv.com/science/human-brains-are-not-as-fast-as-we-previously-thought-study-reveals-7323078
- https://www.sciencealert.com/physics-study-overturns-a-100-year-old-assumption-on-how-brains-work
[^1] : Note : Bien que 175B soit le chiffre largement cité pour le GPT-3 original, le nombre de paramètres pour les modèles plus récents ou les versions spécifiques peut varier et n'est parfois pas officiellement divulgué.





