Die 86 Milliarden Neuronen unseres Gehirns: Können LLMs sie übertreffen?
Das menschliche Gehirn, ein komplexes biologisches System, das über Millionen von Jahren der Evolution perfektioniert wurde, steht im Kontrast zu Large Language Models (LLMs), den neuesten Errungenschaften der künstlichen Intelligenz. Obwohl LLMs beeindruckende Fähigkeiten in der Sprachverarbeitung zeigen, können sie jemals die Komplexität und Fähigkeiten des menschlichen Gehirns übertreffen?

Das menschliche Gehirn wird oft als das kognitiv fortschrittlichste unter den Säugetieren betrachtet, und seine Größe erscheint deutlich größer als aufgrund unserer Körpergröße zu erwarten wäre. Die Anzahl der Neuronen spielt allgemein eine Schlüsselrolle für die Rechenkapazität des Gehirns, doch die gängige Behauptung, dass das menschliche Gehirn 100 Milliarden Neuronen und zehnmal so viele Gliazellen enthält, wurde nie wissenschaftlich bestätigt. Tatsächlich war die genaue Anzahl von Neuronen und Gliazellen im menschlichen Gehirn bis vor kurzem unbekannt.
Laut neuesten Erkenntnissen enthält ein durchschnittliches Gehirn eines erwachsenen Mannes 86,1 ± 8,1 Milliarden Neuronen und 84,6 ± 9,8 Milliarden nicht-neuronale Zellen (Glia). Interessanterweise befinden sich nur 19 % der Neuronen in der Großhirnrinde, obwohl die Rinde 82 % der Masse des menschlichen Gehirns ausmacht. Dies bedeutet, dass die vergrößerte Größe der menschlichen Großhirnrinde nicht mit einer proportionalen Zunahme der Anzahl kortikaler Neuronen einhergeht.
Das Verhältnis von Gliazellen zu Neuronen in verschiedenen Regionen des menschlichen Gehirns ähnelt dem, das bei anderen Primaten beobachtet wird, und die Gesamtzellzahl stimmt mit den Werten überein, die für einen Primaten menschlicher Größe erwartet werden. Diese Ergebnisse stellen die weit verbreitete Ansicht in Frage, dass das menschliche Gehirn im Vergleich zu anderen Primaten eine besondere Zusammensetzung aufweist. Stattdessen legen sie nahe, dass das menschliche Gehirn eine isometrisch vergrößerte Version eines durchschnittlichen Primatengehirns ist – im Wesentlichen ein Primatengehirn, das an die menschliche Größe angepasst ist.
Diese Erkenntnis bietet eine neue Perspektive und veranlasst uns, zu überdenken, was menschliches Denken und kognitive Fähigkeiten wirklich einzigartig macht. Heute nähere ich mich der Frage jedoch aus einem anderen Blickwinkel: Kann unser Gehirn mit Large Language Models (LLMs) verglichen werden, beispielsweise in Bezug auf die Parameteranzahl? Oder ist jeder Vergleich sinnlos, obwohl KI-Forscher und -Entwickler unser Gehirn ständig untersuchen und versuchen, seine Funktionsweise in künstliche Intelligenzsysteme zu übertragen, einfach weil das eine ein chemisches und das andere ein elektronisches System ist? Aber zuerst einige verwandte Hintergrundinformationen.
Wie werden Neuronen gezählt?
Die Schätzung der Anzahl von Neuronen ist eine schwierige Aufgabe, da das Gehirn nicht einheitlich strukturiert ist. Ein Ansatz besteht darin, Neuronen in einer bestimmten Gehirnregion zu zählen und diesen Wert dann auf das gesamte Gehirn zu extrapolieren. Diese Methode birgt jedoch mehrere Probleme:
-
Ungleichmäßige Verteilung
Die Dichte der Neuronen variiert stark zwischen verschiedenen Teilen des Gehirns. Beispielsweise enthält das Kleinhirn, das sich im unteren hinteren Teil des Gehirns befindet, etwa die Hälfte aller Neuronen, obwohl es im Vergleich zum Rest des Gehirns ein deutlich geringeres Volumen aufweist. Dies liegt daran, dass die winzigen Neuronen des Kleinhirns für die Feinabstimmung der motorischen Koordination und anderer automatisierter Prozesse verantwortlich sind. Die zuvor erwähnte Großhirnrinde – verantwortlich für höheres Denken – enthält größere Neuronen, die komplexere Netzwerke bilden. Hier enthält ein Kubikmillimeter etwa 50.000 Neuronen. -
Sichtbarkeit von Neuronen
Neuronen sind so dicht gepackt und kompliziert miteinander verbunden, dass es schwierig ist, sie einzeln zu zählen. Eine klassische Lösung ist die Golgi-Färbung, die von Camillo Golgi entwickelt wurde. Diese Technik färbt nur einen kleinen Teil der Neuronen (normalerweise einige Prozent) an und macht andere Zellen unsichtbar. Dies hilft zwar, eine detailliertere Stichprobe zu erhalten, doch die Extrapolation der Ergebnisse birgt immer noch Unsicherheiten.
Die neueste, genauere Schätzung basiert auf einer innovativen Technik. Forscher lösen die Membranen von Gehirnzellen auf und erzeugen so eine homogene Mischung – eine Art „Gehirnsuppe“ –, in der die Zellkerne der Gehirnzellen unterschieden werden können. Durch Anfärben dieser Zellkerne mit verschiedenen Markern können Neuronen von anderen Gehirnzellen, wie z. B. Glia, getrennt werden. Diese Methode, die oft als isotrope Fraktionator-Technik bezeichnet wird, eliminiert Fehler, die durch Dichteunterschiede zwischen Gehirnregionen entstehen, und liefert ein genaueres Ergebnis für das gesamte Gehirn.
Obwohl diese neue Technologie die Unsicherheit früherer Schätzungen deutlich reduziert, beruht die Methode immer noch auf Stichproben und Extrapolation.
Wie funktioniert das menschliche Gehirn?
Die grundlegenden Bausteine des Gehirns sind Neuronen, von denen wir heute wissen, dass es in einem erwachsenen Gehirn etwa 86 Milliarden gibt. Sie sind jedoch nicht alle gleich – es gibt viele verschiedene Arten von Neuronen, die unterschiedliche Funktionen erfüllen. Neben Neuronen gibt es etwa die gleiche Anzahl von Gliazellen, die unterstützende Funktionen übernehmen, wie z. B. die Versorgung mit Nährstoffen und die Beteiligung an der Immunabwehr.
Die Verbindungen zwischen Neuronen, die Synapsen, machen das Gehirn wirklich besonders. Ein durchschnittliches Neuron bildet etwa 7.000 Synapsen mit anderen Neuronen, was zu insgesamt etwa 600-1000 Billionen synaptischen Verbindungen im Gehirn führt. Diese Verbindungen sind nicht statisch – sie verändern sich ständig, werden während Lernprozessen stärker oder schwächer. Dies wird als synaptische Plastizität bezeichnet.
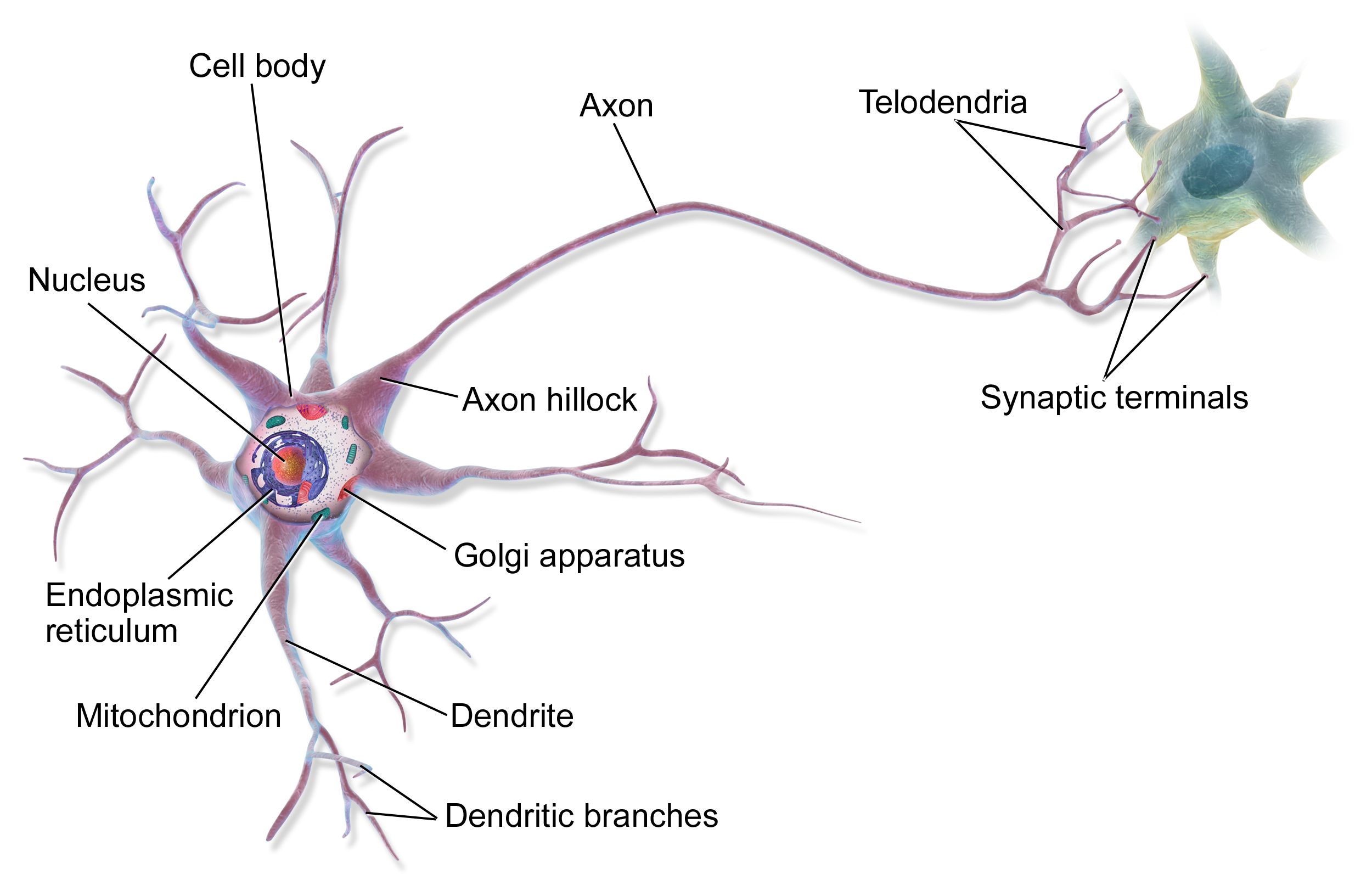
Quelle: Wikipedia
Verschiedene Gehirnregionen sind auf bestimmte Funktionen spezialisiert (wie bereits erwähnt). Das Gehirn ist das Zentrum für bewusstes Denken, Wahrnehmung und motorische Planung. Das Kleinhirn ist der Hauptbereich für motorische Koordination und prozedurales Lernen. Der Hirnstamm reguliert grundlegende Lebensfunktionen, während das limbische System für emotionale Verarbeitung und Gedächtnis zuständig ist.
Die Informationsverarbeitung im Gehirn erfolgt parallel – verschiedene Regionen arbeiten gleichzeitig an verschiedenen Aufgaben. Die Informationsübertragung erfolgt durch eine Kombination aus elektrischen und chemischen Signalen. Wenn ein Neuron aktiviert wird, sendet es einen elektrischen Impuls (Aktionspotential) entlang seines Axons aus und löst an den Synapsen die Freisetzung von Neurotransmittern aus. Diese chemischen Botenstoffe beeinflussen dann die Aktivität des nächsten Neurons.
Der Energieverbrauch des Gehirns ist bemerkenswert effizient – es verbraucht nur etwa 20 Watt, was der Leistung einer Energiesparlampe entspricht. Trotzdem verbraucht das Gehirn etwa 20 % des gesamten Energieverbrauchs des Körpers (obwohl es nur 2 % unserer Körpermasse ausmacht), was zeigt, wie energieintensiv die Informationsverarbeitung ist.
Die Gehirnaktivität ist nicht nur auf neuronaler Ebene organisiert. Es können verschiedene Frequenz-Gehirnwellen (Alpha, Beta, Theta, Delta) beobachtet werden, die die synchronisierte Aktivität großer Neuronengruppen widerspiegeln. Diese Rhythmen spielen wichtige Rollen, beispielsweise bei der Gedächtniskonsolidierung und Aufmerksamkeitsprozessen.
Eine der wichtigsten Eigenschaften des Gehirns ist seine Plastizität – seine Fähigkeit, sich im Laufe des Lebens selbst zu reorganisieren. Dies ist nicht nur die Grundlage des Lernens, sondern ermöglicht auch eine teilweise Erholung nach Verletzungen. Neuroplastizität entsteht durch verschiedene Mechanismen, wie z. B. die Bildung neuer Synapsen, die Stärkung oder Schwächung bestehender Verbindungen und in einigen Fällen sogar die Bildung neuer Neuronen (Neurogenese).
Moderne Forschung zeigt, dass das Gehirn nicht nur mit dem zentralen Nervensystem verbunden ist, sondern auch eng mit dem Darm (der Darm-Hirn-Achse) interagiert und maßgeblich vom Immunsystem beeinflusst wird. Dieses komplexe Netzwerk von Wechselwirkungen erklärt, warum Faktoren wie Ernährung oder Stress einen so tiefgreifenden Einfluss auf die kognitiven Funktionen haben.
Die Wissenschaft steht noch vor vielen Fragen zur Gehirnfunktion. Zum Beispiel verstehen wir noch nicht, wie Bewusstsein entsteht oder wie genau Erinnerungen gespeichert und abgerufen werden. Laufende groß angelegte Gehirnforschungsprojekte wie das Human Brain Project oder die BRAIN Initiative versprechen in naher Zukunft weitere neue Erkenntnisse.
Wie funktionieren Sprachmodelle?
Während die grundlegende Architektur des menschlichen Gehirns ähnlich ist, wobei individuelle Variationen in Struktur und Funktion beobachtet werden (aufgrund von Faktoren wie Neurodiversität oder individuellen Erfahrungen), weisen künstliche Intelligenz-Sprachmodelle ein breites Spektrum in Bezug auf Struktur und Parameter auf. Diese Modellunterschiede können durch die Verwendung unterschiedlicher Architekturen (wie Transformer versus rekurrente Netzwerke) oder durch das Training mit unterschiedlichen Datensätzen entstehen. Es gibt jedoch einige Bereiche, in denen sie mehr oder weniger übereinstimmen. Ich werde versuchen, diese zu umreißen.
Transformer-basierte Sprachmodelle (wie GPT- oder Llama-Modelle) sind grundlegend aus Transformer-Blöcken (Layern) aufgebaut, die Encoder- und Decoder-Teile (oder oft nur Decoder-Teile) enthalten. Jeder Block beherbergt mehrere Komponenten, die unterschiedliche Aufgaben erfüllen. Die wichtigsten davon sind der Multi-Head-Self-Attention-Mechanismus und die Feed-Forward-Neuronale-Netzwerk-Schicht. Neben diesen Komponenten spielen auch Layer-Normalisierung, Dropout und Positionscodierung eine wichtige Rolle. Das Wesen des Self-Attention-Mechanismus besteht darin, dass er die Beziehungen zwischen Eingabewörtern dynamisch erlernt, während das Feed-Forward-Netzwerk eine nichtlineare Transformation durchführt.
Wenn wir über die Parameteranzahl sprechen (einer der wichtigsten Determinanten von Sprachmodellen, oft sogar im Namen des Modells enthalten), beziehen wir uns eigentlich auf die Summe der lernbaren Gewichte und Bias des Modells. Diese Parameter bestimmen, wie das Modell Informationen verarbeitet, und werden während des Trainings (Lernprozesses) optimiert. Die Anzahl der Parameter hängt von mehreren Faktoren ab:
-
Anzahl der Transformer-Blöcke: Größere Modelle enthalten typischerweise mehr Transformer-Blöcke. Beispielsweise verwenden GPT-3s 175 Milliarden Parameter [^1] 96 Blöcke (Layer), während die Llama 2 70-Milliarden-Parameter-Version 80 Blöcke verwendet. Die Tiefe der Blöcke beeinflusst die Parameteranzahl erheblich.
-
Größe des Hidden State: Dies ist ein Vektor, der Informationen innerhalb eines bestimmten Blocks repräsentiert und bestimmt, wie viele Informationen das Modell gleichzeitig verarbeiten kann. Je größer diese Zahl, desto mehr Parameter werden in den Transformer-Blöcken benötigt.
-
Anzahl der Attention Heads: Multi-Head-Attention ermöglicht es dem Modell, dieselbe Eingabe aus verschiedenen Perspektiven zu analysieren. Jeder Attention Head benötigt zusätzliche Parameter.
Betrachten wir konkrete Zahlen: In einem typischen Transformer-Block sind die Parameter verteilt auf:
-
Die Gewichtsmatrizen des Attention-Mechanismus (Query-, Key-, Value-Matrizen)
-
Die Gewichte und Bias des Feed-Forward-Netzwerks
-
Die Skalierungs- und Verschiebungsparameter der Layer-Normalisierung
-
Parameter für die Positionscodierung (sowohl für gelernte als auch für sinusförmige Versionen)
Ein interessanter Aspekt ist die Rechenkomplexität: Die Rechenkosten des Self-Attention-Mechanismus wachsen quadratisch mit der Sequenzlänge. Das bedeutet, dass, obwohl das Modell viele Parameter hat, nicht alle Parameter gleichzeitig aktiv sind während der tatsächlichen Verarbeitung. Sparse-Attention-Techniken versuchen, dieses Problem zu lösen.
Daher ist die Parameteranzahl allein nicht unbedingt ein gutes Maß für die Fähigkeiten eines Modells. Ein kleineres Modell mit einer besseren Architektur kann oft ein größeres, aber weniger effizientes Modell übertreffen. Die Modellleistung wird auch anhand von Metriken wie Genauigkeit, F1-Score, BLEU-Score oder PERPLEXITY bewertet. Dies ist vergleichbar damit, dass es im menschlichen Gehirn nicht nur auf die Anzahl der Neuronen oder Synapsen ankommt, sondern auch auf deren Organisation und die Qualität der Verbindungen zwischen ihnen.
Kann das Gehirn anhand spezifischer Werte mit einem Sprachmodell verglichen werden?
Obwohl es verlockend sein mag, das aktuelle Niveau der künstlichen Intelligenz zu messen, indem man ihre Leistung und ihr Wissen mit unserem Gehirn vergleicht, legen die obigen Beschreibungen nahe, dass, obwohl die primäre Quelle für die Entwicklung künstlicher Systeme die Untersuchung der Struktur und Funktion unseres Gehirns ist (da es ein funktionierendes Beispiel ist – so trivial das auch klingen mag, es ist eine entscheidende Tatsache), der Vergleich alles andere als einfach ist. Ein direkter Vergleich von LLM-Parametern mit entweder der Anzahl der Neuronen oder Synapsen ist nicht möglich, da die beiden Systeme auf grundlegend unterschiedlichen Funktionsprinzipien und Architekturen basieren. Trotz der grundlegenden Unterschiede können jedoch einige Analogien zwischen den beiden Systemen gezogen werden.
Neuronen vs. LLM-Layer
-
LLM-Layer ähneln in gewisser Weise der hierarchischen Struktur des Gehirns, in der die Informationsverarbeitung auf mehreren Ebenen erfolgt. Im Gehirn ist die Hierarchie jedoch eher funktional und in spezialisierte Regionen unterteilt, während Layer in LLMs Abstraktionsebenen darstellen.
-
Neuronen sind lokal unabhängige Einheiten, aber global in Netzwerken organisiert, während LLM-Layer durch den Attention-Mechanismus global voneinander abhängig sind. Self-Attention ermöglicht einen globalen Informationsfluss innerhalb eines Layers.
Synapsen vs. LLM-Parameter
-
LLM-Parameter ähneln Synapsen in dem Sinne, dass beide die Stärke des Informationsflusses beeinflussen, wenn auch durch unterschiedliche Mechanismen.
-
Synapsen verändern sich dynamisch und passen sich an, während LLM-Parameter nach dem Training statisch sind. Feintuning ermöglicht es, Parameter wieder zu ändern, aber dies entspricht immer noch nicht der dynamischen Natur von Synapsen. Die synaptische Stärke ändert sich über Langzeitpotenzierung (LTP) oder Langzeitdepression (LTD), die dynamische bioelektrochemische Prozesse sind.
Was repräsentiert LLM-Parameter besser?
-
Weder Neuronen noch Synapsen repräsentieren LLM-Parameter genau, aber die nächste Analogie sind Synapsen, da sie auch Verbindungen und die Stärke des Informationsflusses regulieren. Mit diesem Ansatz ist es interessant festzustellen, dass die Anzahl der Synapsen im Gehirn um Größenordnungen größer ist (100-1000 Billionen Synapsen im Vergleich zu 70 Milliarden bis potenziell über 1 Billion Parameter in den größten LLMs).
-
Synapsen sind jedoch weitaus komplexer und dynamischer als LLM-Parameter. Synapsen sind nicht nur einfache Gewichte; sie regulieren Verbindungen durch komplexe bioelektrochemische Prozesse, die sich dynamisch basierend auf Aktivität und Erfahrung verändern.
Warum ist die Analogie ungenau?
-
Operationelle Unterschiede:
-
Das Gehirn weist biologischen Parallelismus auf und verarbeitet kontinuierliche Signale, während LLMs auf diskreten, digitalen Berechnungen beruhen, die von numerischen Prozessoren (GPUs/TPUs) durchgeführt werden. Im Gehirn werden Berechnungen durch biochemische Prozesse und elektrische Signale durchgeführt.
-
-
Lernmechanismus:
-
Das Lernen im Gehirn ist dynamisch und effizient, selbst mit wenigen Daten. Mustererkennung und Verstärkung spielen eine entscheidende Rolle. Menschliches Lernen ist oft One-Shot oder Few-Shot und ermöglicht die Verallgemeinerung aus wenigen Beispielen. Verstärkendes Lernen ist auch im Gehirn wichtig.
-
LLM-Training erfordert massive Datenmengen und Rechenressourcen. LLMs sind weniger in der Lage, aus wenigen Beispielen zu verallgemeinern.
-
-
Energieeffizienz:
-
Das Gehirn ist extrem energieeffizient. Das Trainieren und Ausführen von LLMs ist enorm energieintensiv, um Größenordnungen mehr als der Energieverbrauch des menschlichen Gehirns.
-
-
Repräsentation:
-
Repräsentationen im Gehirn sind verteilt und dynamisch, während sie in LLMs eher wie statische Vektoren sind.
-
Das Gehirn ist mit Bewusstsein und subjektiver Erfahrung verbunden, was LLMs derzeit fehlt.
-
-
Architektur:
-
Die hierarchische Organisation des Gehirns ist viel komplexer und modularer, wobei verschiedene Regionen unterschiedliche Funktionen erfüllen. Diese Modularität ist in LLMs weniger ausgeprägt.
-
Feedback-Schleifen spielen im Gehirn eine wichtige Rolle, während dies für die meisten LLMs weniger charakteristisch ist.
-
-
Anpassung und Flexibilität:
-
Das Gehirn ist aufgrund der Neuroplastizität hochgradig anpassungsfähig und flexibel, während LLMs weniger in der Lage sind, sich nach dem Training an Veränderungen anzupassen.
-
Das Gehirn kann sich an seine Umgebung anpassen, eine Fähigkeit, die in LLMs weniger offensichtlich ist.
-
-
Emotionen und Motivation:
-
Emotionen spielen eine entscheidende Rolle bei der Entscheidungsfindung und beim Lernen im Gehirn, eine Dimension, die in LLMs fehlt.
-
Motivation ist entscheidend für das Verhalten im Gehirn, eine weitere Dimension, die in LLMs fehlt.
-
Zusammenfassung
Wie wir gesehen haben, sind die Analogien zwischen LLM-Layern und der hierarchischen Struktur des Gehirns oder zwischen LLM-Parametern und Synapsen, obwohl bestimmte Analogien gezogen werden können, begrenzt. Somit hat die im Titel des Artikels gestellte Frage „Die 86 Milliarden Neuronen unseres Gehirns: Können LLMs sie übertreffen?“ keine einfache Antwort.
Die beiden Systeme basieren auf grundlegend unterschiedlichen Funktionsprinzipien und Architekturen. LLMs fehlt Bewusstsein, subjektive Erfahrung und sie können nicht in der Weise aus wenigen Beispielen verallgemeinern, wie es das Gehirn kann.
Die zukünftige Forschung im Bereich der künstlichen Intelligenz wird sich wahrscheinlich auf die Weiterentwicklung der LLM-Fähigkeiten konzentrieren, wodurch sie möglicherweise näher an die Funktionsweise des menschlichen Gehirns herangeführt werden. Dies könnte die Entwicklung dynamischerer Lernmechanismen, eine höhere Energieeffizienz, bessere Verallgemeinerungsfähigkeiten und vielleicht die Implementierung einer Form von Bewusstsein umfassen. Ein tieferes Verständnis der Gehirnfunktion könnte dazu beitragen, effizientere und intelligentere KI-Systeme zu entwickeln.
Es ist jedoch wichtig zu bedenken, dass LLMs keine Kopien des menschlichen Gehirns sind, sondern einen anderen Weg zur Erreichung von Intelligenz darstellen. Das Verständnis der Unterschiede zwischen den beiden Systemen ist unerlässlich, um die Chancen, die die künstliche Intelligenz bietet, verantwortungsvoll und effektiv zu nutzen. In Zukunft könnte die Synergie zwischen Neurowissenschaften und künstlicher Intelligenz neue Horizonte für beide Bereiche eröffnen.
Quellen:
- https://pubmed.ncbi.nlm.nih.gov/19226510/
- https://www.nature.com/scitable/blog/brain-metrics/are_there_really_as_many/
- https://www.sciencealert.com/scientists-quantified-the-speed-of-human-thought-and-its-a-big-surprise
- https://www.ndtv.com/science/human-brains-are-not-as-fast-as-we-previously-thought-study-reveals-7323078
- https://www.sciencealert.com/physics-study-overturns-a-100-year-old-assumption-on-how-brains-work
[^1]: Hinweis: Obwohl 175 Mrd. die weithin zitierte Zahl für das ursprüngliche GPT-3 ist, können die Parameterzahlen für neuere Modelle oder bestimmte Versionen variieren und werden manchmal nicht offiziell bekannt gegeben.





